
In the voice top meeting ICASSP, the poster paper of Alibaba's voice interactive intelligence team proposed an improved feedforward sequence memory neural network structure called deep feedforward sequence memory neural network (DFSMN). The researchers further combined the deep feedforward sequence memory neural network with low frame rate (LFR) technology to construct an LFR-DFSMN speech recognition acoustic model.
The model can achieve significant performance improvement in the recognition system of the most popular long-short-time memory unit-based bidirectional cyclic neural network (BLSTM) in both English recognition and Chinese recognition tasks of large vocabulary. Moreover, LFR-DFSMN has obvious advantages over BLSTM in terms of training speed, model parameter amount, decoding speed, and model delay.
Research Background
In recent years, deep neural networks have become the mainstream acoustic model in large vocabulary continuous speech recognition systems. Since speech signals have a strong long-term correlation, it is currently popular to use a cyclic neural network (RNN) with long-term correlation modeling capabilities, such as LSTM and its deformed structure. Although the cyclic neural network has strong modeling ability, its training usually adopts BPTT algorithm, and there are problems of slow training speed and gradient disappearance. Our previous work proposed a novel non-recursive network structure called feedforward sequential memory networks (FSMN), which can effectively model the long-term correlation in the signal. Compared to cyclic neural networks, FSMN training is more efficient and can achieve better performance.
In this paper, we further propose an improved FSMN structure based on the previous work of FSMN, which is called deep feedforward sequence memory neural network (Deep-FSMN, DFSMN). By adding jump connections between adjacent memory modules of the FSMN, we ensure that the network high-level gradient can be well transmitted to the lower layer, so that the network with deep training will not face the problem of gradient disappearing. Further, considering the application of DFSMN to the actual speech recognition modeling task, it is necessary to consider not only the performance of the model, but also the computational complexity and real-time performance of the model. In response to this problem, we propose to combine DFSMN and low frame rate (LFR) for accelerated model training and testing. At the same time, we designed the structure of DFSMN. By adjusting the order of the DFSMN memory module to realize the delay control, the acoustic model based on LFR-DFSMN can be applied to the real-time speech recognition system.
We verified the performance of DFSMN in a number of large vocabulary continuous speech recognition tasks, including English and Chinese. In the current popular 2,000-hour English FSH mission, our DFSMN can achieve an absolute 1.5% and less model parameters than the current mainstream BLSTM. On the 20,000-hour Chinese database, LFR-DFSMN can achieve a relative performance improvement of over 20% compared to LFR-LCBLSTM. Moreover, LFR-DFSMN can flexibly control the delay. We have found that delay control to 5 frames of voice can still achieve better performance than LFR-LCBLSTM with 40 frames delay.
FSMN review
The model structure of the earliest proposed FSMN is shown in Figure 1(a). It is essentially a feedforward fully connected neural network. By adding some memory blocks to the hidden layer to model the surrounding context information. So that the model can model the long-term correlation of timing signals. The proposed FSMN is inspired by the filter design theory in digital signal processing: any Infinite Impulse Response (IRR) filter can be approximated by a high-order Finite Impulse Response (FIR) filter. From the perspective of the filter, the loop layer of the RNN model as shown in Fig. 1(c) can be regarded as the first-order IIR filter as shown in Fig. 1(d). The memory module used by FSMN as shown in Figure 1(b) can be regarded as a high-order FIR filter. Thus, the FSMN can also model the long-term correlation of the signal as effectively as the RNN, and since the FIR filter is more stable than the IIR filter, the FSMN is simpler and more stable than the RNN training.
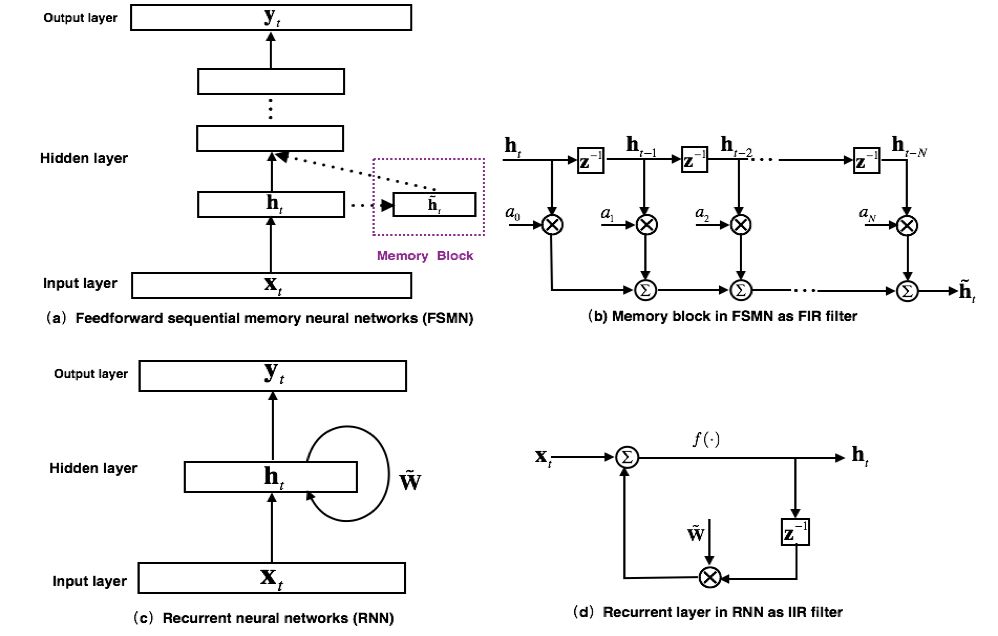
Figure 1. FSMN model structure and comparison with RNN
According to the selection of the coding coefficients of the memory module, it can be divided into: 1) scalar FSMN (sFSMN); 2) vector FSMN (vFSMN). sFSMN and vFSMN, as the name implies, use scalars and vectors as the coding coefficients of the memory module, respectively. The expressions of the sFSMN and vFSMN memory modules are as follows:
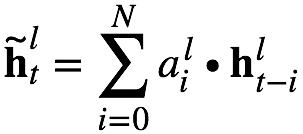

The above FSMN only considers the impact of historical information on the current time, we can call it a one-way FSMN. When we consider both historical information and the impact of future information on the current moment, we can extend the one-way FSMN to obtain a two-way FSMN. The coding formulas for the two-way sFSMN and vFSMN memory modules are as follows:
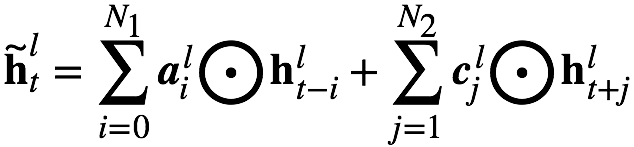
Here 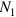 with
with 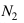 Represents the order of look-back and the order of look-ahead. We can enhance the ability of FSMN to model long-term correlation by increasing the order and by adding memory modules in multiple hidden layers.
Represents the order of look-back and the order of look-ahead. We can enhance the ability of FSMN to model long-term correlation by increasing the order and by adding memory modules in multiple hidden layers.
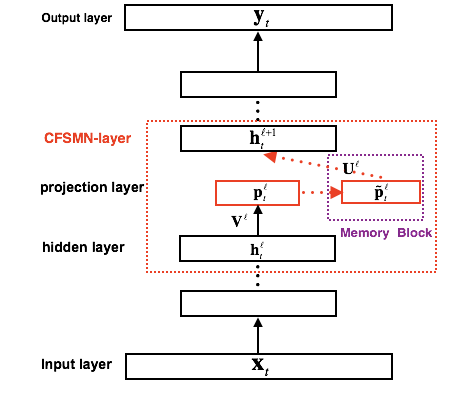
Figure 2. Block diagram of cFSMN
Compared to FNN, FSMN needs to take the output of the memory module as an additional input to the next hidden layer, which will introduce additional model parameters. The more nodes the hidden layer contains, the more parameters are introduced. By combining the idea of ​​low-rank matrix factorization, we propose an improved FSMN structure called Compact FSMN (cFSMN). FIG. 2 is a structural block diagram of a cFSMN in which a lth hidden layer includes a memory module.
For cFSMN, a low-dimensional linear projection layer is added after the hidden layer of the network, and memory modules are added to these linear projection layers. Further, cFSMN makes some changes to the coding formula of the memory module, and by explicitly adding the output of the current moment to the expression of the memory module, it is only necessary to use the expression of the memory module as the input of the next layer. This can effectively reduce the parameter amount of the model and speed up the training of the network. Specifically, the formulas for the one-way and two-way cFSMN memory modules are as follows:
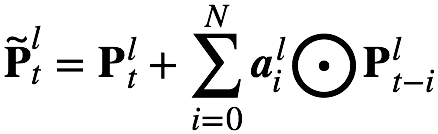
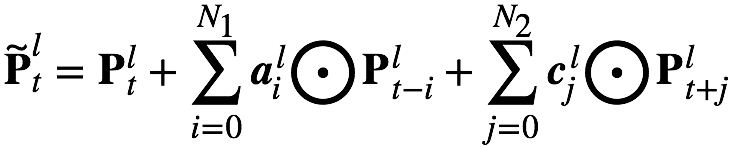
Introduction to DFSMN
Figure 3. Block diagram of the Deep-FSMN (DFSMN) model
Figure 3 is a block diagram of the network structure of Deep-FSMN (DFSMN), which is further proposed. The first box on the left represents the input layer, and the last box on the right represents the output layer. We add a jump connection between the memory modules of the cFSMN (represented by the red box) so that the output of the low-level memory module is directly added to the upper memory module. In this way, during the training process, the gradient of the upper memory module is directly assigned to the lower memory module, so that the gradient disappearance caused by the depth of the network can be overcome, so that the deep network can be stably trained. We have also made some modifications to the expression of the memory module. By referring to the idea of ​​dilation convolution [3], we introduce some stride factors in the memory module. The specific calculation formula is as follows:
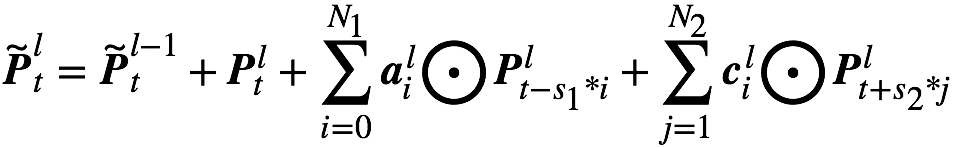
among them 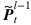 Express
Express 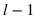 The output of the layer t memory at the tth moment.
The output of the layer t memory at the tth moment. 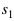 with
with 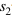 The coding step factor representing the history and the future time, respectively, for example, means that a value is taken as an input every other time when encoding the history information. In this way, a farther history can be seen in the same order, so that long-term correlation can be modeled more effectively. For real-time speech recognition systems, we can control the delay of the model by flexibly setting the future order. In extreme cases, when we set the future order of each memory module to 0, we can achieve no delay. An acoustic model. For some tasks, we can tolerate a certain delay, we can set a smaller future order.
The coding step factor representing the history and the future time, respectively, for example, means that a value is taken as an input every other time when encoding the history information. In this way, a farther history can be seen in the same order, so that long-term correlation can be modeled more effectively. For real-time speech recognition systems, we can control the delay of the model by flexibly setting the future order. In extreme cases, when we set the future order of each memory module to 0, we can achieve no delay. An acoustic model. For some tasks, we can tolerate a certain delay, we can set a smaller future order.
LFR-DFSMN acoustic model
In the current acoustic model, the input is the acoustic feature extracted from each frame of the speech signal. The duration of each frame of speech is usually 10 ms, and there is a corresponding output target for each input speech frame signal. Recently, a low frame rate (LFR) modeling scheme has been proposed to predict the average output target of the target output of these speech frames by binding the speech frames at adjacent moments as inputs. Three frames (or more frames) can be stitched in a specific experiment without losing the performance of the model. Thus, the input and output can be reduced to one-third or more, which can greatly improve the calculation of the acoustic score and the efficiency of decoding when the speech recognition system is serviced. Combining LFR with the DFSMN proposed above, we constructed the LFR-DFSMN-based speech recognition acoustic model as shown in Figure 4. After several experiments, we finally determined that a DFSMN with 10 layers of DFSMN layer + 2 layers of DNN was used as the acoustic model. The input and output are LFR, which reduces the frame rate to one-third.
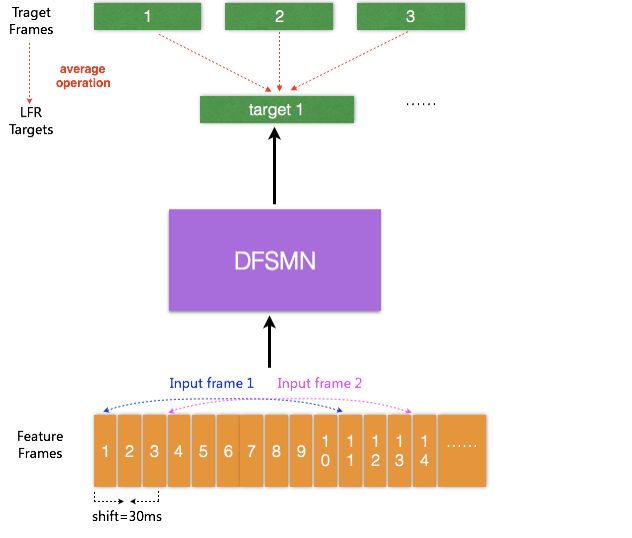
Figure 4. Block diagram of the LFR-DFSMN acoustic model
Experimental result
English recognition
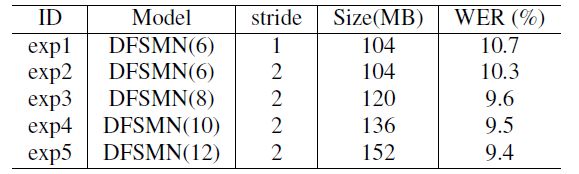
We validated the proposed DFSMN model on the 2,000-hour English FSH mission. We first verified the impact of DFSMN's network depth on performance. We verified that DFSMN includes 6, 8, 10, and 12 DFSMN layers. The recognition performance of the final model is shown in the following table. By increasing the depth of the network we can get a significant performance boost.
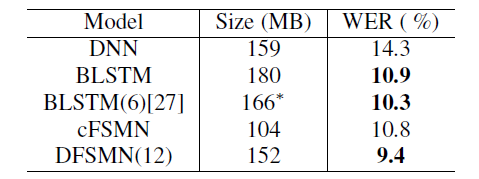
We also compared some mainstream acoustic models, the results are shown below. From the results, DFSMN has not only a smaller amount of parameters than the most popular BLSTM, but also an absolute performance improvement of 1.5% in performance.
2. Chinese recognition
Regarding the Chinese recognition task, we first experiment on the 5000 hour task. We verified the use of the bound phoneme state (CD-State) and the bound phoneme (CD-Phone) as the output layer modeling unit. Regarding the acoustic model, we compared the delay controlled BLSTM (LCBLSTM), cFSMN and DFSMN. For the LFR model, we use CD-Phone as the modeling unit. The detailed experimental results are as follows:

For the baseline LCBSLTM, the LFR is similar in performance to the traditional single-frame prediction, and the advantage is three times more efficient. Compared with traditional single-frame prediction, cFSMN with LFR can not only improve the efficiency, but also obtain better performance. This is mainly because LFR destroys the timing of the input signal to a certain extent, and the memory mechanism of BLSTM is more sensitive to timing. Further, we explored the impact of network depth on performance. For the previous cFSMN network, when the network depth is deepened to 10 layers, there will be a certain performance degradation. For our newly proposed DFSMN, the 10-layer network can still achieve performance improvement compared to the 8 layer. Ultimately, we can achieve a relative performance improvement of over 20% compared to the baseline LFR-LCBLSTM model.
In the table below we compare the training time of LFR-DFSMN and LFR-LCBLSTM with the real-time factor (RTF) of the decoding. From the results, we can increase the training speed by 3 times, and at the same time reduce the real-time factor to nearly one-third.

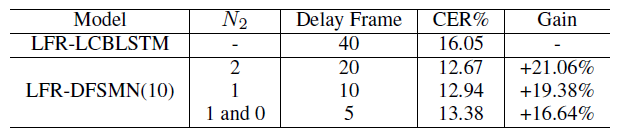
Another factor to consider for speech recognition systems is the delay of the model. The original BLSTM needs to wait for the entire sentence to get the output for decoding. LCBLSTM is an improved structure that can control the delay of decoding. The current LFR-LCBLSTM has a delay frame of 40 frames. For DFSMN, the number of frames of delay can be flexibly controlled by the filter order of the design memory module. Finally, when there is only 5 frame delays, LFR-DFSMN can still achieve better performance than LFR-LCBLSTM.
Lcd Bar Display,Shelf Edge Display,Stretched Bar Lcd,Stretched Bar Display
APIO ELECTRONIC CO.,LTD , https://www.displayapio.com