
This article is transferred from: Tencent excellent map
When it comes to artificial intelligence (AI) people are always easy to relate to words like omniscience and omnipotence. A lot of science fiction movies about AI cast a mysterious color on artificial intelligence. As strong as the "Matriarchs" and "Mechanical Enemy", the AI ​​must turn over to be the master of all humanity. In the slightly weaker "Mechano", EVA knows how to use good looks to deceive second-level programmers and kill the owner to escape the ascension. The most incompetent can be stupid cute like WALL E can play, send gifts and talk about love.
In fact, when the term artificial intelligence came into being at the 1956 Dartmouth conference, the goal was to make the machine's behavior look like the "strong" artificial intelligence that humans exhibited. However, the research on artificial intelligence is highly technical and professional, and each branch is in-depth and unrelated, and therefore involves a very wide range. It is this complex property that leads people to always bump into the research process of artificial intelligence, repeatedly experiencing over-optimistic waves and extremely pessimistic winter. Today, it is still only a long-term goal to achieve omnipotent and versatile strong artificial intelligence.
Although the current level of technology is far from being able to achieve strong artificial intelligence, in some very specific areas, weak artificial intelligence technology is experiencing unprecedented rapid development, reaching or surpassing the highest level of human beings. For example, Deep Blue and Alpha Go beat world champions in chess and Go respectively. For example, natural language understanding, speech recognition, and face recognition are close to reaching or even surpassing the recognition level of ordinary people. Although these weak artificial intelligence technologies cannot really reason, understand, and solve problems, the “judgments†they give given tasks seem to be intelligent. It is these seemingly “weakly weak†artificial intelligence technologies that quietly change every aspect of human life. They accomplish more and more "simple tasks" with points and areas, providing people with more concise, convenient and safe services.
Face recognition is one of many “weak and weak†artificial intelligence technologies. Recognizing people’s identities by watching people’s faces is a simple matter for every normal person. If the difficulty of forcibly recognizing face recognition is comparable to that of playing chess, no one will feel that face recognition is more difficult. However, from the computer point of view, face recognition is far more advanced than Go's single-step decision-making, at least in the complexity of the input data. As shown in Figure 1(a), an image of Angelababy appears to the computer as a digital matrix as shown in Figure 1(b). Each element of the numeric matrix is ​​in the range of 0-255. Generally, the input image required by the face recognition algorithm is at least above and large may be reached. Theoretically different possible input common species (each pixel has a range of 0-255). The possible upper limit of any single-step move of Go is (there are only three cases: black box, white box, and no box for each board), which is far less than face recognition. Whether it is Go or face recognition, making optimal decisions by traversing the complete input space is completely unacceptable in terms of computational complexity.
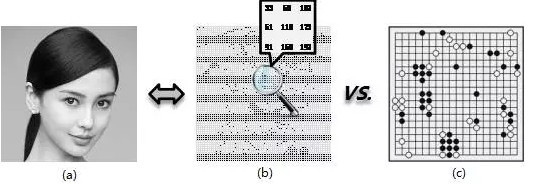
Figure 1: Digital face recognition VS. Go single-step decision
In fact, for almost all artificial intelligence problems, how to use higher level abstractions to understand input and make quicker decisions is the key to solving the problem. The core technology “deep learning†that has led the new wave of artificial intelligence in the past decade is such a method. It can abstract high-dimensional input data blocks continuously through several layers and hundreds of artificial neural networks. Understand and ultimately make "smart" decisions. Deep learning techniques alone may still be difficult to accomplish with omnipotent and omnipotent "strong" artificial intelligence, but it is an elixir for accomplishing any specific "weak" intelligence task. It is to see such a huge potential for deep learning technology. Internet giants Google, Facebook, and Microsoft have taken the lead in the deployment. Domestic Internet leader BAT has spared no effort to make technical reserves. As a top-level machine learning R&D team within Tencent, it is also investing in elites. Manpower focuses on R&D and product landing of deep learning technologies.
This paper focuses on face recognition as an example to introduce the application of deep learning technology, and the knowledge and sharing of the face recognition technology and even the entire field of artificial intelligence after the excellence map team has accumulated over the past five years.
Review - The "Shallow" Age of Face Recognition
Before introducing the application of deep learning technology in face recognition, we first look at the "shallow" era face recognition technology before the rise of deep learning technology. As mentioned earlier, high-dimensional input is a common problem in all artificial intelligence problems. The academic community calls it “The curse of dimensionalityâ€. In fact, early researchers in the automatic face recognition technology of machines tried to use some very simple geometric features for face recognition, as shown in Figure 2 (please forgive the quality of the picture, taken from a face recognition in 1993). The cornerstone of the field [1]).

Figure 2: Face recognition based on geometric features
Such simple ideas have the advantage of less feature dimensions, so they do not suffer from dimensionality catastrophes. However, due to poor stability, poor discrimination, and difficulty in automation, this practice has long been abandoned. Researchers have found that designing various geometric features is not as accurate as comparing the direct comparison of pixel regions. It is called template matching technology. However, the direct comparison of pixel errors has the disadvantage that it is easy to think of, and the different face regions are not as important as they are for distinguishing people's identities. In fact, the study [2] showed that the eyebrows and eyes are the most important areas to distinguish between human identities, followed by the mouth, and the cheek area contains a limited number of identity information. As shown in Figure 3, the most difficult thing for humans to identify is the face with the eyebrows and eyes removed.
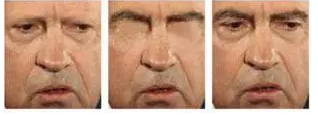
Figure 3: Importance of face recognition in different regions
In order to solve such problems, face recognition for a long time is very dependent on the learning of discriminative features. The most representative work is fisherfaces [3]. The so-called discriminative information is the unique feature, just like in Figure 4. As shown, Jackie Chan's big nose, Yao Chen's mouth, Li Yong's signature horse face, Yao Ming's magic smile. All in all, as long as you can find your unique "temperament" will be able to better understand you.

Figure 4: Discriminating faces
The idea of ​​discriminatory features is very intuitive, effective and has achieved some success. However, due to the very unstable pixel characteristics of human faces, different shooting devices and shooting scenes, different lighting conditions, and shooting angles can cause huge differences in the pixels of the same face. It is difficult to find a stable and unique face feature under various complicated influence factors. To solve these problems, researchers began to study image descriptors that are more stable than simple pixel values. One of the more mainstream descriptors, the Gabor descriptor, draws on the process of preprocessing visual information in the visual cortex of the human brain. There are two main operations for processing visual information in the cerebral cortex. One is linear operation in simple cells and the other is non-linear convergence in complex cells. Figure 5 shows the brain-like visual information processing process called HMAX [4] proposed by Prof. Poggio, director of the Artificial Intelligence Laboratory at the MIT School of Brain and Cognitive Science:
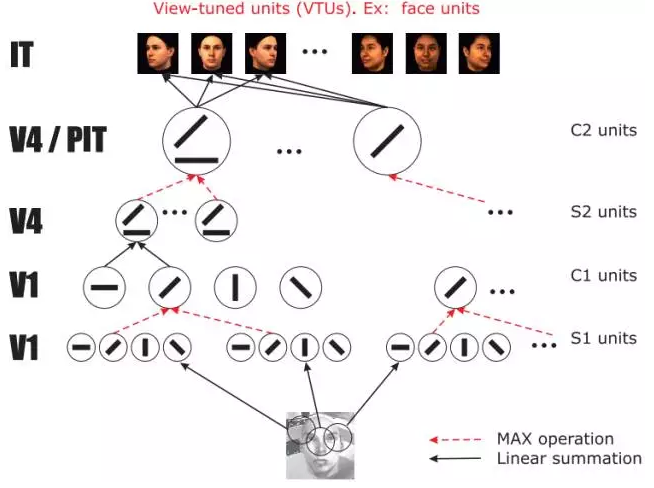
Figure 5: HMAX image information processing
The simple units "S1 units" and "S2 units" perform an operation called Gabor wavelet filtering. The complex units "C1 units" and "C2 units" perform an operation called Max Pooling that takes the maximum value of the local area. In fact, apart from directly using the pre-set Gabor filter, HMAX is equivalent to a four-layer neural network. In fact, it has preliminary prototypes of modern depth models.
In the “shallow†era before the birth of deep learning, face recognition researchers continued to improve the preprocessing process, use better descriptors, and extract more discriminative features, which are slowly improving the ability of computers to recognize human faces. . However, until the deep learning turned out, the various methods of face recognition in the “shallow†era are still far behind the human face recognition capabilities of human beings.
Hug - the "deep" era of face recognition
To give the computer complete face recognition capabilities, in addition to knowing people, there are actually a few very important pre-processing processes. As shown in Figure 6, the complete face recognition algorithm needs to be able to find out which faces are in the image. The academic circles call it face detection. Where is the nose and mouth, the academic community calls it the facial feature point positioning? Finally, it is to extract the discriminative features mentioned above to identify the identity, that is, face recognition in a narrow sense.

Figure 6: Complete automatic face recognition process
Before the appearance of deep learning, the research on the three sub-tasks of face detection, feature point location and face recognition are relatively independent. From the beginning of the 1990s to around 2010, after continuous exploration, the researchers found a combination of more effective features and methods to solve problems for each sub-task. However, because the researcher needs to design different characteristics according to the characteristics of each subtask itself and choose different machine learning methods, the development of the technology is relatively slow.
From around 2012, due to the rapid development of deep learning in the field of machine vision, the “deep†era of face recognition officially kicked off. In a short span of four years, methods based on deep convolutional neural networks continue to refresh the world records of artificial intelligence algorithms in these three sub-tasks. The dazzling variety of technologies and methods in the face of “recognition†in face recognition seem to have become history between pages. Face recognition researchers do not need to worry about design features, nor do they need to worry about what kind of learning algorithms are needed later. The accumulated process of all experiences is converted into deep neural network algorithm automatic learning process. The biggest advantage of this formal deep learning algorithm is that it automatically learns the most useful features for specific tasks!
Figure 7: Face recognition
Investigating whether a single “weak†artificial intelligence technology is mature and reaching or even surpassing the average human level should be a more general criterion. Speaking of this, I have to mention a Faced Face in the Wild (LFW) database for face recognition. In 2014, Facebook used a deep learning approach called DeepFace, which for the first time approached human recognition levels on the LFW database (DeepFace: 97.35% VS. Human: 97.53%). The results are shown in Figure 8:

Figure 8: DeepFace Deep Learning Network
“Talk is cheap, show me the codeâ€. Since DeepFace became famous in the field of face recognition, researchers have seen the dawn of human recognition. With the development and expansion of several open source deep learning projects (such as CAFFE, TORCH, and TensorFlow), the method based on deep learning has really sprung up across the entire face recognition field. Facts have also proved that deep learning can indeed be achieved. In just one year later, there are many methods based on deep learning that exceed human recognition capabilities in the LFW database. For example, the facial recognition algorithm of TUTU achieved the world's first in 15 years. The 99.65% accuracy rate.
Why is deep learning so magical that it can govern the rivers and lakes in just a few years? Regardless of technical details, the two most important factors in principle are: hierarchical abstraction and end-to-end learning.
In reviewing the history of “shallow†age face recognition methods, we have introduced methods based on geometric features (Figure 2) and discriminative features based methods (Figure 4). The following figures are undoubtedly all about some abstraction of human face. Since the search space for the original image input is huge, only a proper abstraction can narrow down the scope of the search, and ultimately a reasonable decision can be made. It is difficult or even impossible for a complex concept to abstract all the structures through a layer of abstraction. Deep layers of neural networks provide a natural mold for bottom-up, step-by-step abstraction. As long as enough data is input into a deep neural network with a multi-layer structure and informed of the output you want, the network can automatically learn the abstract concepts of the middle tier. As shown in Figure 9, the curious researchers will be able to The features in the neural network that identify 1000 objects were visualized:

Figure 9: Visualization results of deep neural network features
It can be seen from the figure that the first layer of the deep neural network is somewhat similar to the Gabor features that human scientists have accumulated over many years of experience. The second layer learns more complex texture features. The characteristics of the third floor are more complex and some simple structures have begun to emerge, such as wheels, honeycombs, and human heads. The performance of the output of the fourth and fifth layers of the machine is enough to make people mistakenly believe that it has certain intelligence and can respond to some specific abstract concepts such as dogs, flowers, clocks, and even keyboards. Researchers have accumulated features that have been designed for years or even decades, such as Gabor and SIFT. In fact, they can be learned automatically through deep neural networks (as shown in Figure 9, “Layer 1â€) and even automatically learn its human “dadâ€. Indescribably higher levels of abstraction. In a sense, artificial intelligence scientists are the parents of the machine and need to "teach" the baby to know the world. Everyone wants to have a clever baby who only uses it to "know what it is" and it slowly digests and "knows why." Deep neural networks are like a smart machine. Your baby will learn, abstract, and summarize.
End-to-end learning can be a bit "square" at first glance, but it can be understood simply as a global optimum. Figure 7 summarizes that in the “shallow†era, the sub-problems of face recognition need to be completed in two or more steps, and the multiple steps are optimized independently. This is a typical greedy rule, it is difficult to achieve the overall optimum. In fact, it is difficult to reach the global optimal solution due to the optimization algorithm deep neural network, but its optimization goal is globally optimal. The successful experience of deep learning in various tasks in recent years shows that baby robots also need to have dreams, and directly target the “best†global optimal goal to learn, that is, less than optimal solutions are also far better than small ones. Fragmented local greedy algorithm. In order to achieve true "strong" artificial intelligence, deep neural networks still have a long way to go. Star's famous quote is also applicable to nervous babies. What is the difference between a dream and a salted fish?
Attack - "Evolution" of Youtu's grandmother model
With the development of machine learning techniques for deep neural networks, the human recognition capabilities of all machine learning algorithms beyond the reach of the three or four years ago on the LFW face database have long been exceeded. Although Youtu has achieved 99.65% of the LKW's good results that exceed the human average, we clearly understand that the brush library is still far from enough. The application in the actual scene is more important and more challenging. The various application scenarios and application types have been subdivided according to landing requirements in order to achieve various breaks in face recognition tasks under various scenarios. At present, in the landing application, the common types of photo scenes are life photos, selfies, surveillance videos, access gates, photos of westerners and others, as shown in FIG. 10 .

Figure 10: Common face recognition scene types
There are a large number of face photos on the Internet, and a large number of Internet face data tagged with identities have also been accumulated through the search engine optimization map. This part of the data is the best in terms of the number of people, the number of images, and the diversity of data, which provides the basic conditions for the development of the excellent figure face recognition technology. With the maturing of face recognition technology, a large number of application requirements emerge in the actual business, such as the micro banking business's core business. The conference sign-in business involves the comparison of passport photos and mobile phone selfies, and public security monitoring. Requires video surveillance data and passport photo comparison. There are great differences in the face images obtained under different scenes. How to quickly adjust the face recognition model and quickly land in various scenarios becomes a very challenging problem.
In order to gain an upper hand in the increasingly fierce market competition, Youtu established its own set of methodology in scene migration and adaptation based on three years of deep recognition of face recognition and deep learning. This methodology can be summarized in one sentence: the "evolution" of the grandmother model. There are two key points in this sentence. First of all, we need to build a powerful face recognition model that is suitable for general scenes, that is, the grandmother model. Secondly, the grandmother model adapts to face recognition in new scenes through “evolutionâ€.
Build grandmother model family
The grandmother model does not specifically refer to a deep neural network model but a type of neural network model with certain structural characteristics. Therefore, the more appropriate name is the grandmother model family. For different application scenarios, users may have different needs for the speed and accuracy of face recognition. The grandmother model family must be like an arsenal, containing both machine guns that can be fired quickly and atomic bombs that require long periods of powerful cooling.
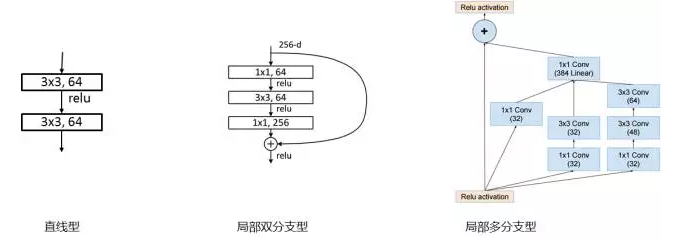
Figure 11: Local structure classification of deep neural networks
At present, the most popular deep neural network structure can be roughly classified into three categories: 1. Linear type (such as AlexNet, VGGNet); 2. Local double-type (ResNet); 3. Local multi-type type (GoogleNet). The straight-line network structure design is the simplest, but when the network depth exceeds 20, the network structure will become difficult to optimize. The local multi-branch network model has strong capabilities and higher computational efficiency, but the design is also the most complex. In the early days of establishing the grandmother model family, we chose ResNet, a local two-branch network with relatively strong model design and relatively simple design, to build a grandmother model family for face recognition. On the one hand, ResNet has strong learning ability and is the latest research progress in the field of deep learning last year. With a 152-tier ResNet deep network, MSRA took the first place in the single most successful ImageNet 2015 contest in the image recognition field. On the other hand, the ResNet design is relatively simple. One of the biggest features is that the recognition ability is basically proportional to the depth of the neural network. The depth of the neural network is directly related to the computational complexity. This provides great convenience for training multiple models with different recognition accuracy and running speed to build a grandmother model family. When the network structure of the grandmother model was selected, we trained it on the dataset with the largest amount of Internet life to ensure universal face recognition capabilities of the grandmother model, as shown in FIG. 12 .
Figure 12: Excellent figure face recognition grandmother model
After the establishment of the local dual-branch model family, we also started to use more complex local multi-branch components to further improve the model efficiency and enrich our grandmother model family.
The "evolution" of the grandmother model
Migration learning is the mainstream method proposed in the field of artificial intelligence in recent years to handle recognition problems in different scenarios. The deep neural network model has better migratory learning ability than simple methods in the shallower age. There is also a simple and effective migration method. In general, it is the pre-training of basic models on complex tasks, and the fine tuning of models on specific tasks. Applying to the face recognition problem, you only need to fine tune the trained good figure grandmother model on the new data of the new scene.
Figure 13: Evolution of Grandma Grandma Model
This traditional migration learning method can really help the grandmother model to complete the face recognition task in the new scene better. But this can only be regarded as specific, and it is impossible to feed back the new information learned from the migration study to the grandmother model. The specific model after migration can only be applied in specific scenarios, and the performance on the original set may even decline significantly. In the “shallow†era without deep learning, the model does not have the ability to handle multiple scenes at the same time, which may be the best way to adapt to the new scene. However, in practice, we have found that due to the powerful expressiveness of deep neural networks, it is entirely possible to maintain the universal performance of the grandmother model during the transfer learning process. Incremental learning is used to adapt the new scene, and the ability to recognize other people under the new scene can be maintained. This results in a better universal grandma model, which is the “evolution†of the Grandma grandma model. .
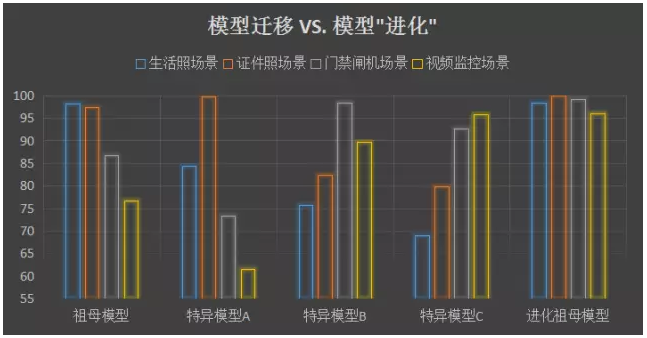
With the continuous accumulation of data under various scenarios, the grandma grandma model will continue to evolve and become even more powerful.
In the future, we will continue to accumulate face recognition capabilities under new scenarios based on business needs. And try to extend the magical "evolution" capability of this deep neural network to more problems. Through continuous evolution, the grandmother's model has become more and more clever, and perhaps one day we can really create an omnipotent and all-powerful "Ultimate Brain!"
This article is authorized reproduced from Tencent excellent plans, if you need to reprint please get the original author authorization
Industrial Lighting Led Driver
Industrial Lighting Led Driver
IP65 or IP67 for waterproof, products applicable to Industrial and high bay light for outdoor, also pass the UL/FCC/TUV/RCM/CB/CE Certified. can do the dimming 0-10V/PWM/RX. With the short circuit, over temperature, over voltage protaction. Stable performance, can be used for a long time.Good water resistance, the use of safe and stable.
Parameter:
Input voltage: 100-277vac / 100-347V
output voltage: 25-40vdc / 27-42vdc / 35-45vdc / 50-70vdc / 12Vdc / 24vdc /36V/48V
current: 100mA-8000mA.
Power factor: >0.9
IP degree: IP65/ IP67
Dimming:0-10V / PWM / RX / DALI.
>=50000hours, 5 years warranty.

FAQ:
Question 1:Are you a factory or a trading company?
Answer: We are a factory.
Question 2: Payment term?
Answer: 30% TT deposit + 70% TT before shipment,50% TT deposit + 50% LC balance, Flexible payment
can be negotiated.
Question 3: What's the main business of Fahold?
Answer: Fahold focused on LED controllers and dimmers from 2010. We have 28 engineers who dedicated themselves to researching and developing LED controlling and dimming system.
Question 4: What Fahold will do if we have problems after receiving your products?
Answer: Our products have been strictly inspected before shipping. Once you receive the products you are not satisfied, please feel free to contact us in time, we will do our best to solve any of your problems with our good after-sale service.
Surge Protection Device,0-10V Dimming Led Driver,Led Grow Light Driver,Switching Power Supply
ShenZhen Fahold Electronic Limited , https://www.fahold.com